
Snipaste贴图结合OCR文字识别:打造信息收集工作流 #
引言 #
在信息爆炸的时代,我们每天都会接触到海量的文本信息:PDF研究报告、网页文章、电子书段落、软件界面提示,甚至是图片中的说明文字。传统的信息收集方式——手动键入或复制粘贴——不仅效率低下,容易出错,而且在面对不可直接复制的文本(如图片、PDF扫描件)时更是束手无策。作为一款功能强大的截图工具,Snipaste的核心“贴图”功能,能够将任何屏幕内容冻结为始终置顶的悬浮窗口,这为解决此难题提供了一个绝佳的“中转站”或“缓冲区”。然而,贴图本身并未解决文本提取的问题。本文将系统性地阐述,如何将Snipaste的贴图功能与OCR(光学字符识别)技术强强联合,打造一套从“捕获”到“识别”,再到“整理与应用”的自动化信息收集工作流。无论您是学术研究者、内容写作者、程序员还是知识管理者,这套方法都将显著提升您处理文本信息的效率与准确性。
第一部分:理解工作流的基石——Snipaste贴图与OCR技术 #
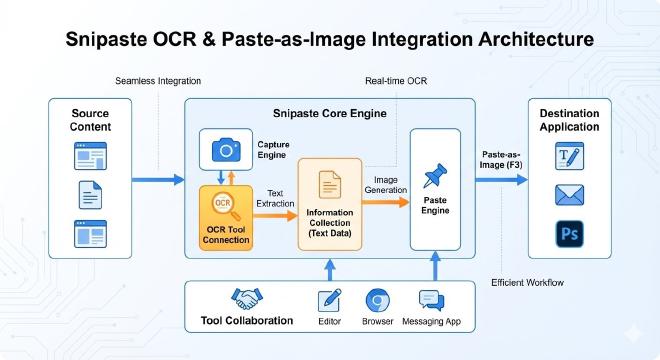
1.1 Snipaste贴图:不止于“悬浮” #
在深入工作流之前,有必要重新审视Snipaste贴图功能的本质。它远非一个简单的“截图后停留在屏幕上”的功能。
- 信息暂存与上下文保持:贴图可以将关键信息(如参考文献、数据表格、代码片段、操作步骤)从原始环境中剥离出来,同时保持其视觉完整性,并悬浮在当前工作窗口之上。这避免了在多个窗口或标签页之间频繁切换,确保核心参考信息始终在视线范围内。
- 多信息源并行对比:您可以同时贴出来自不同来源的多个图片(例如,不同论文中的图表、多个商品的规格参数),进行直观的横向比较,这是传统复制粘贴文字难以实现的。
- 非侵入式信息展示:贴图窗口不会干扰您在其他应用程序(如Word、IDE、浏览器)中的主要操作,实现了参考与创作的无缝并行。
理解贴图的这些特性,是将其作为OCR工作流“前哨站”的关键。它负责完成信息的精准捕获与初步可视化整理。
1.2 OCR技术:从图像到可编辑文本的桥梁 #
OCR(Optical字符识别)技术能够自动分析图片中的像素排列,识别出文字内容,并将其转换为计算机可编辑、可搜索的文本格式。
- 本地OCR vs. 在线OCR:
- 本地OCR:依赖安装在您电脑上的软件或库(如某些PDF阅读器的内置OCR、专业OCR软件Tesseract引擎)。优势是速度快、隐私性好(数据不出本地),但对复杂排版或低质量图片的识别精度可能有限。
- 在线OCR:通过调用云端API(如百度OCR、腾讯云OCR、Google Cloud Vision)提供服务。优势通常是识别准确率更高,尤其是对中文、混合排版支持更好,且无需本地计算资源,但需要网络连接,并涉及数据上传的隐私考量。
- 集成OCR的工具:许多现代效率工具已内置或深度整合了OCR功能,例如:
- 天若OCR(Windows知名开源工具)
- Quicker(效率神器,可通过动作库安装OCR动作)
- uTools(插件化工具,拥有丰富的OCR插件)
- Edge浏览器(右键菜单“复制图片中的文本”)
- 微信/QQ(截图后识别文字)
在本工作流中,我们将主要利用这些集成OCR的工具,与Snipaste进行配合,实现无缝衔接。
第二部分:构建核心工作流——从截图到可编辑文本 #
本章节将详细拆解工作流的每一个步骤,并提供多种工具组合方案。
2.1 方案一:Snipaste + 系统级OCR工具(推荐) #
这是最通用、最快捷的方案,适用于大多数Windows 10/11用户。
步骤清单:
- 捕获与贴图:使用Snipaste(默认快捷键
F1)截取包含目标文本的屏幕区域。截图后,直接按下贴图快捷键(默认F3),该图片便会成为一个悬浮贴图窗口。 - 调用系统OCR:将鼠标焦点置于任何可以输入文本的地方(如记事本、Word、浏览器地址栏、聊天窗口)。按下
Win + Shift + S启动Windows系统截图,但此时我们目的不是截图,而是利用其后续功能。 - 选择“文本识别”模式:在屏幕顶部弹出的工具栏中,选择 “文本识别” 按钮(一个带有文字线条的图标)。此时鼠标会变成十字准星。
- 框选贴图文字:直接用这个十字准星,去框选Snipaste贴图窗口中您想要识别的文字区域。
- 自动识别与粘贴:松开鼠标后,系统OCR会在后台瞬间完成识别,并自动将识别出的文字粘贴到您当前光标所在的位置。
优势分析:
- 无缝流畅:操作路径极短,几乎在2-3秒内完成从贴图到文本粘贴的全过程。
- 系统原生:无需安装额外软件,利用Windows自带功能,稳定可靠。
- 隐私安全:识别过程由系统完成,无需上传网络。
局限性:对某些特殊字体、极度模糊或背景复杂的图片,识别率可能下降。
2.2 方案二:Snipaste + 第三方OCR工具(如天若OCR、Quicker) #
此方案功能更强大,提供翻译、格式化、固定识别区域等高级功能。
步骤清单(以天若OCR为例):
- 准备贴图:同样,先使用Snipaste截取并贴图(
F1->F3)。 - 唤醒OCR工具:启动天若OCR(通常设置为全局快捷键,如
F4)。 - 框选识别:天若OCR激活后,屏幕会出现一个半透明覆盖层和十字准星。直接用准星框选Snipaste贴图上的文字区域。
- 处理与输出:松开鼠标,天若OCR会弹出一个结果面板,显示识别出的文字。您可以在此面板中进行翻译、排版修正、分段等操作,然后一键复制或发送到指定窗口。
工作流场景示例——阅读外文文献:
- 在PDF阅读器中看到一段复杂的英文段落。
- 用Snipaste截取该段落并贴图(
F3)。 - 按下
F4启动天若OCR,框选贴图。 - 在天若OCR的结果面板中,直接点击“翻译”按钮,中英文对照立刻呈现。
- 将翻译结果复制,粘贴到您的笔记软件中。
2.3 方案三:Snipaste + 浏览器内置OCR #
适用于主要从网页获取信息的场景。
步骤清单(以Microsoft Edge为例):
- 捕获与贴图:从网页上截取无法直接复制的文本区域(比如受版权保护的页面、图片形式的文字),用Snipaste贴图。
- 拖拽至浏览器:将Snipaste贴图窗口直接拖拽到Edge浏览器的标签页区域或地址栏。浏览器会将该贴图作为一个新的标签页打开。
- 使用右键OCR:在新打开的图片标签页中,在图片上右键单击,选择 “复制图片中的文本”。
- 粘贴使用:切换到您的笔记软件,粘贴即可。
优势:Edge浏览器的OCR对网页文字优化极好,识别准确率极高,且步骤简单直观。
第三部分:高级技巧与场景化应用 #
掌握了基本工作流后,我们可以通过一些高级技巧和场景化设计,让其威力倍增。
3.1 打造“一键OCR”超级快捷键 #
如果您频繁使用某一套组合(如方案二),可以利用AutoHotkey、Quicker等自动化工具,将“激活Snipaste截图->贴图->激活OCR->框选”这一系列操作压缩到一个快捷键内。例如,设置按下 Ctrl+Shift+Q 后,自动完成截图、贴图,并触发OCR工具的框选状态,您只需手动框选即可。这需要一定的脚本编写能力,但能带来效率的质变。
3.2 信息的中转与批量处理 #
贴图可以作为信息的“流水线中转站”。
- 批量识别:您可以连续截取多段文本并贴出多个贴图窗口。然后依次对每个贴图进行OCR识别,将所有文本汇总到一个文档中。这比每截一次图就识别一次、复制一次更为有序。
- 信息预筛选:在阅读长文档时,快速贴出所有您觉得重要的图表、段落。全部贴完后,再统一进行OCR识别和整理,避免阅读思路被频繁的识别操作打断。
3.3 整合到知识管理系统 #
识别出的文本不是终点,将其有效纳入个人知识库才是目标。
- 即时归档:在OCR识别并复制文本后,立即打开您的笔记软件(如Obsidian、Notion、OneNote),建立一个以当前主题命名的页面或区块,将文本粘贴进去。
- 添加元数据:在粘贴的文本下方,简单记录信息来源(原贴图可暂时保留作为视觉参考)、捕获日期以及关键标签(如
#论文笔记、#产品灵感、#代码参考)。 - 链接关联:如果您之前在网站上阅读过《Snipaste截图后如何高效管理、命名与归档图片文件》,可以将其中关于文件命名的逻辑借鉴到文本笔记的标题命名上,保持管理风格的一致性。同样,处理设计类文本时,可以关联《专业设计师如何利用Snipaste取色器进行高效色彩管理》中的色彩信息管理思路。
3.4 特定职业场景应用 #
- 学术研究:
- 文献综述:从不同PDF论文中贴出核心论点、实验数据和方法描述,OCR识别后并列对比,快速提炼异同点。
- 引用管理:快速抓取参考文献条目(常为图片格式),识别后直接导入Zotero或EndNote。
- 内容创作与新媒体运营:
- 素材收集:从社交媒体、竞品网站贴图收集文案风格、用户评论、热点话题,OCR后存入素材库。
- 快速引用:引用网络图片中的名言金句,无需手动打字。
- 编程与开发:
- 代码片段收集:从技术博客、文档或错误提示框中贴图保存代码示例或报错信息。
- 文档处理:将老旧扫描版的技术手册或API文档图片转换为可搜索的文本。
- 外语学习:
- 生词摘录:在阅读外文电子书或网页时,随时贴图不认识的句子,OCR识别后,使用词典工具或天若OCR内置翻译快速学习。
第四部分:潜在问题与优化策略 #
4.1 识别精度优化 #
- 截图质量是根本:确保截图清晰、文字区域无严重变形。Snipaste在截图时,可以按住
Shift进行等比例缩放,按住Ctrl进行中心点扩展,以精确框选。 - 预处理贴图:对于背景杂乱、对比度低的贴图,可以先用Snipaste自带的简单标注工具(如矩形框、马赛克)将无关区域遮盖或高亮文字区域,再交给OCR识别,能有效提升精度。
- 选择合适的OCR引擎:如果系统OCR识别某类文字(如手写体、特殊符号)效果差,可切换至在线的、更专业的OCR引擎尝试。
4.2 工作流流畅度优化 #
- 内存管理:开启大量Snipaste贴图会占用一定内存。对于已经处理完的贴图,及时关闭(鼠标悬停后点击关闭按钮或按
Esc)。 - 快捷键自定义:将Snipaste的截图、贴图快捷键设置为最顺手的位置(如
Ctrl+Shift+A截图,Ctrl+Shift+Q贴图),避免与其它软件冲突。关于快捷键的深度配置,可以参考我们之前的文章《Snipaste快捷键大全:从入门到精通的终极快捷键指南》。 - 贴图透明度调节:在处理OCR时,可以将贴图透明度适当调低(选中贴图后,用鼠标滚轮或按
Ctrl + F1/F2),使其既能看清文字,又不完全遮挡下层的OCR工具界面。
常见问题解答 (FAQ) #
Q1: Snipaste本身有OCR功能吗? A1: 截至目前,Snipaste官方版本尚未内置OCR功能。它的定位是卓越的截图、贴图和标注工具。本文的工作流正是利用了其顶尖的贴图功能作为“前端”,与专业的OCR工具“后端”相结合,从而发挥出“1+1>2”的效能。
Q2: 使用在线OCR服务,我的截图隐私安全吗? A2: 这是一个重要的考量。对于涉及敏感信息(如个人证件、机密文档、私有代码)的截图,强烈建议使用本地OCR方案(如Windows系统OCR、本地部署的Tesseract)或可信任的离线OCR软件。对于公开网络信息、学术文献等,使用信誉良好的大厂在线OCR服务(如百度、腾讯云)通常是安全的,但最好阅读其隐私条款。
Q3: 这个工作流在Mac系统上可行吗? A3: 核心思路完全可行,但具体工具需要替换。Snipaste有Mac版,其贴图功能一致。OCR方面,Mac用户可以利用:
- 系统原生:在预览(Preview)中打开图片,使用“工具”->“文字识别”功能。
- 快捷指令:配合“截屏”和“从图像获取文本”操作,创建自动化工作流。
- 第三方工具:如CleanShot X(内置OCR)、PopClip(配合OCR插件)。
Q4: 识别出的文本格式混乱(如分段错误、多余空格)怎么办? A4: 这是OCR的常见问题。解决方案有:
- 使用高级OCR工具:如天若OCR、Quicker中的OCR动作,通常提供“格式化文本”、“合并换行”等后处理选项。
- 粘贴到中间处理器:先将文本粘贴到VS Code、Sublime Text等代码编辑器,利用其多光标编辑、列选择或正则表达式查找替换功能,快速清理格式。
- 专用文本整理工具:使用像“TextFixer”这类在线工具进行快速格式化。
Q5: 如何将识别出的文本和原始贴图关联保存? A5: 建议在笔记软件中采用“嵌入式”记录法:
- 在笔记中粘贴识别好的文本。
- 在文本下方,使用笔记软件的“插入图片”功能,将Snipaste贴图对应的原始截图文件插入(截图时Snipaste可以自动保存文件到指定目录)。
- 或者,在文本旁记录下原始截图文件的名称或路径。这样既能享受可编辑文本的便利,又能随时回溯原始图像上下文。
结语 #
Snipaste的贴图功能与OCR技术的结合,绝非简单的功能叠加,而是一种工作范式的革新。它将我们从“手动搬运工”的角色中解放出来,构建了一条从视觉信息到数字化文本的高速自动化管道。这套工作流的核心价值在于其灵活性与普适性——您可以根据自己的需求、习惯和操作系统,自由搭配不同的OCR工具,定制出最适合自己的信息收集方案。
正如我们之前探讨的《超越基础截图:探索Snipaste中鲜为人知的隐藏功能》一文所揭示的,Snipaste的潜力远不止于简单的屏幕捕捉。当您将贴图视为一个动态的信息“抓手”,并将其与外部强大的工具链(OCR、翻译、自动化脚本、知识管理软件)连接时,您才能真正释放这款截图软件的全部生产力。无论是应对严谨的学术研究,还是处理日常的信息洪流,这套方法都能帮助您更加从容、高效地获取、处理和吸收知识,最终将碎片信息转化为系统的个人能力与见解。
本文由Snipaste官网提供,欢迎浏览Snipaste下载网站了解更多资讯。